

Результати дослідження науковців з Базельського та Невшательського університетів у Швейцарії продемонстрували, що Великі мовні моделі на базі ШІ досі погано імітують людей.
За словами одного з авторів дослідження Лукаса Бієтті, LLM спілкуються не так, як люди. Науковці протестували ChatGPT-4, Claude Sonnet 3.5, Vicuna та Wayfarer.
Спочатку вони незалежно один від одного порівняли розшифровки телефонних розмов між людьми з імітацією розмов між Великими мовними моделями. Далі вони перевірили, чи можуть люди відрізнити телефонні розмови від спілкування між LLM.
Результати продемонстрували, що більшість учасників без проблем розрізняли розмови між людьми та ШІ. Як пояснюють дослідники, під час розмови між людьми присутня певна частка наслідування, оскільки люди переважно адаптують слова під співрозмовника, однак вона зазвичай доволі тонка, щоб її вловити. LLM надто схильні до наслідування і люди це розрізняють. Це називається надмірним вирівнюванням.
У фільмах з погано прописаним сценарієм діалоги часто звучать штучно. У таких випадках сценаристи не надто опікуються реалістичністю, обмежуючись лише необхідними змістовними словами.
У реальних повсякденних розмовах більшість людей переважно використовують короткі слова, що називаються “дискурсивними маркерами”. Це такі слова, як от “так”, “ну”, “ніби”, “у будь-якому разі”. Ці слова виконують певну соціальну функцію, сигналізуючи про зацікавленість, приналежність, відношення або значення для іншої людини. LLM досі погано орієнтуються у використанні цих слів, використовуючи їх по різному і часто неправильно. Це допомагає людям розрізняти їх.
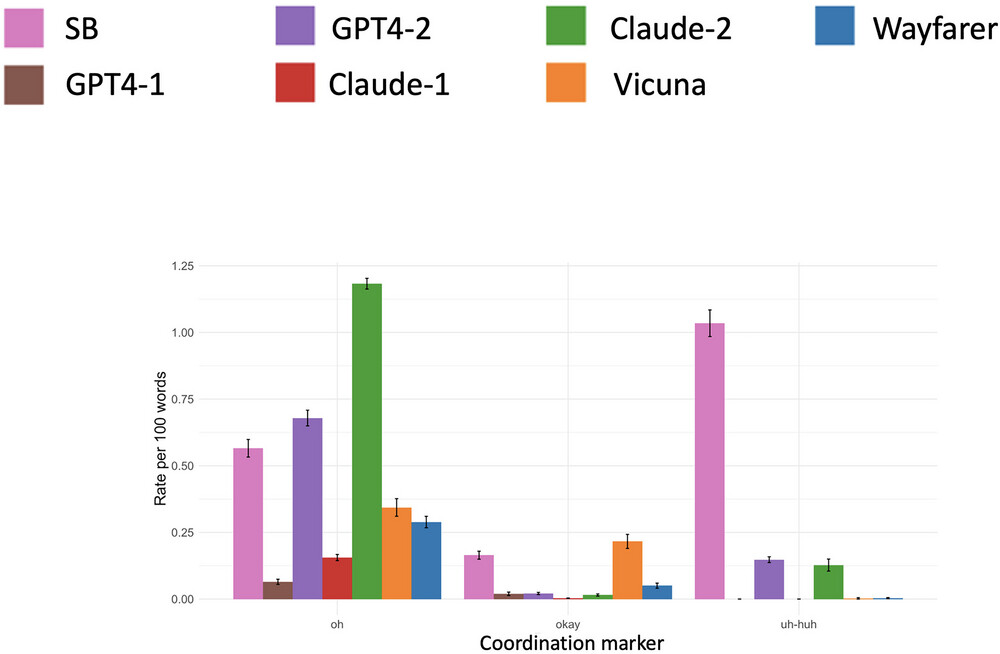
Перш ніж перейти до суті, люди зазвичай починають з якихось відсторонених речей, типу “Привіт”, “Як справи”, “Приємно тебе бачити”. Розмова може початись з чогось незначного, перш ніж перейти до конкретного питання. Такі переходи також залишаються складними для LLM.
Те саме стосується і завершення розмови. Ми зазвичай не обриваємо розмову різко, щойно передали інформацію співрозмовнику. LLM також погано справляються з цим.
“Сучасні великі мовні моделі поки що нездатні досить добре імітувати людей, щоб постійно обманювати нас. Удосконалення у великих мовних моделях, швидше за все, дозволять скоротити розрив між людським та штучним спілкуванням, але ключові відмінності, ймовірно, збережуться”, — робить висновок Лукас Бієтті.
Результати дослідження опубліковані у журналі Cognitive Science
Джерело: TechXplore
