11 грудня на платформі Netflix розгорнулися неабиякі різдвяні клопоти у комедії “Людина проти немовляти” — формально продовженні мінісеріалу “Людина проти бджоли” (2022), у якому Ровен Аткінсон вступив у конфронтацію з нестерпною комахою. Цього разу легендарному містеру Біну буде знову несолодко — йому належить дати раду непосидючому малюку.
Плюси:
фірмовий Ровен Аткінсон; тепла різдвяна атмосфера; тут є приводи для хорошого настрою; комфортний хронометраж серій;
Мінуси:
достатня присутність умовностей; крінжове CGI-маля; наївність гумору, як і передбачуваність деяких комедійних моментів сподобається не усім; перегини з продакт-плейсментом;
7/10
Оцінка ITC.ua
“Людина проти немовляти”/ Man Vs Baby
Жанр різдвяна комедія Творці: Ровен Аткінсон, Вільям Девіс У ролях: Ровен Аткінсон, Сюзанна Філдінг, Стів Едж, Суніл Патель, Роберт Батерст, Еллі Вайт, Ангус Імрі, Сунетра Саркер, Алана Блур, Клоді Блейклі Прем’єра Netflix Рік випуску 2025 Сайт IMDb
Тревор Бінглі працює завгоспом у сільській школі та планує провести Різдво разом з колишньою дружиною Джесс та вже дорослою донькою Медді. Однак цим планам не судилося здійснитися, адже Джесс відгукується на пропозицію свого нинішнього бойфренда вирушити на Барбадос. До того ж цей нахаба пообіцяв оплатити навчання Медді, в той час як Бінглі животіє у бідності без найменших перспектив змінити ситуацію на краще.
Але, о різдвяне диво, стражденному надходить вельми вигідна пропозиція від компанії домонагляду, де Тревор досі зареєстрований як робоча одиниця. Там змінилося керівництво і, схоже, ніхто не в курсі про ту катастрофу, яка відбулася з невдачливим працівником минулого разу, коли він влаштував погром через бджолу.
Нині ж йому необхідно доглядати за пентхаусом непристойно заможної пари в самісінькому центрі Лондона. Та ця, на перший погляд, проста робота стає для Бінглі черговим кошмаром, адже йому доведеться ще й опікуватися немовлям-Ісусом з різдвяної шкільної вистави, котрого ніхто з батьків так і не забрав.
Як і у випадку з “Людиною проти бджоли” слід констатувати, що формальний другий сезон шоу — це типовий Аткінсон. Нехай із застереженнями, але досі в хорошому сенсі. Звісно, 70-річний актор очікувано не дає тієї енергійної фізичної комедії, що була присутня за часів “Містера Біна” або принаймні “Джонні Інгліша” — тутешній виступ досить спокійний, стриманий і абсолютно точно можна сказати, що виконаний на досвіді. Але і цього цілком достатньо, щоб приємно провести час біля екрана.
Фірмовий аткінсонівський гумор — завжди в тій чи іншій мірі реінкарнація містера Біна. Недарма ж тут є пряма згадка про культового персонажа в одному з діалогів, причому її видали ще на етапі трейлера.
От і цього разу ми стикаємося саме з таким гумором: позамежна кількість абсурдно-кумедних ситуацій, боротьба з вітряками, продиктована загальною недолугістю та водночас героїчною винахідливістю героя, плюс звичні вибрики та гримаси. Звідси і виринає очевидна передбачуваність та наївність місцевого комізму. Але в цьому ж і його магія — ви точно знаєте, чого чекати від містера Аткінсона.
Останньому точно не звикати до ситуацій, в яких він опиняється, і тут навіть не обов’язково згадувати Біна. Різдвяно-святкового коміка згадуємо в ефектному камео з “Реального кохання” (2003). Заклопотаного приготуванням вечері — у дотепній післятитровій сцені під “У печері гірського короля” Едварда Гріга у “Джонні Інгліші: Перезавантаження” (2011). Такого, що бавиться з собакою (причому людським серцем, а не черевиком — оцініть, що називається, сміливість гумору тоді і зараз), чи дуркує з немовлям — у “Щурячих перегонах” (2001). Тож коли ми кажемо, що Аткінсон виступає на досвіді, це в прямому сенсі так і є.
Попри те, що комедійний складник серіалу ґрунтується на вищевказаних наївності та передбачуваності, в першу чергу ця історія про добро. Тобто про те, чого нашому світу зараз ой як не вистачає. А як інакше, якщо “Людина проти немовляти” — стовідсотково про різдвяний контент. Усе тут кричить про затишну, максимально безпечну святкову атмосферу (а це вже те, чого вкрай не вистачає усім нам, українцям), про передсвяткові закупи чи просто якусь приємну метушню. Зрештою, це про теплі сімейні зустрічі.
Вистачає на екрані і кричущих умовностей, які виглядають як відверта непродуманість.
Наприклад, дивує воістину суперменська стійкість маля до холоду. Як і його крінжова неприродність у тих епізодах, що вимагали використання CGI; тут доречно згадати про сцену з малюками у “Флеші” (2023), якщо ми чомусь заговорили про дісішну супергероїку.
А про кінцівку, що передбачає тріумфальне єднання абсолютно чужих людей, годі й згадувати. Але чи варто сильно зважати на такі прикрощі у різдвяній комедії з Ровеном Аткінсоном — на це питання кожен глядач має дати відповідь самостійно.
В усьому іншому це досить приємна невибаглива розвага, спрямована підсилити ваш святковий настрій. В “Людині проти бджоли” Тревор Бінглі часом нагадував Кевіна Маккалістера, який постарів. У “Людині проти немовля”, як і в “Сам удома” (1990), теж усе крутиться на тлі святкової атмосфери. Проте в якийсь момент багатостраждальний герой змушує згадати вже не про малого шибеника з класики різдвяної комедії, а про славнозвісних дослідників калу Саломона Самсоновича та Африкана Свиридовича.
Комфортний хронометраж у вигляді 4 епізодів тривалістю у 25 хвилин (виключення становить хіба трохи довший фінальний) дозволяє говорити про максимальне розслаблення біля екрана без затягнутості, в той час як наявні недоліки не встигають надокучити. Та й Аткінсон все ще перебуває у непоганій комедійній формі: кожен прикрий провал його персонажа ризикує обернутися крихітним гумористичним тріумфом для цієї вкрай простої, але теплої історії.
Висновок:
Дивитися шанувальникам Ровена Аткінсона та тим, кому не вистачає затишного різдвяного настрою.
Ажіотаж навколо “Одіссеї” Крістофера Нолана зріс із запуском 6-хвилинного прологу. Наразі відео транслюють на показах окремих фільмів в IMAX, але, звісно, поява екранного запису в мережі не забарилась.
Очевидно, студія робить все можливе, аби видалити запис, однак його, якщо постаратись, ще можна відшукати в мережі. Далі — спойлери до перших 6 хвилин “Одіссеї”.
Перші 6 хвилин — це, по суті, пролог до “Одіссеї”, що показує кінець Троянської війни. Фільм починається з питання: “Ви чули історію про коня?”. Далі нам показують кадри самої дерев’яної споруди й троянського солдата, який залазить на неї й встромляє спис, щоб перевірити на безпеку — хоча фактично ранить одного зі схованих людей всередині. Одіссей швидко закриває чоловікові рот, щоб той не видав себе криком від болю.
Для тих, хто знайомий з історією Гомера, подальші події не будуть сюрпризом: коли настає ніч, греки вилазять з коня та вбивають охоронців. Дизайн костюмів демонструє розумний контраст між греками та троянцями: Одіссей та його люди одягнені в темні обладунки, ідеальні для вторгнення, тоді як троянці носять білу форму та маски, аби уникнути відчуття індивідуальності. Залишку охоронців вдається підняти тривогу, але греки встигають відкрити ворота. Далі Одіссей одягає свій грецький шолом і готується приєднатися до битви, яка тепер вирує по всьому місту.
Сам пролог завершується морськими пейзажами з натяком на основну пригоду далеко від Трої та кадром із циклопом. Раніше ми писали, що спеціально для фільму були розроблені ляльки-аніматроніки, які зображали міфічних істот в натуральних розмірах.
Критики тим часом активно діляться своїми враженнями й, судячи з їх слів, “Одіссея” має стати “фільмом століття”, не менше.
“Пролог до “Одіссеї” просто вражає. Те, що це перший фільм, знятий на 100% на плівкові камери IMAX, вже само по собі є диким, але те, як це виглядає на екрані, — неймовірно. Звукове оформлення викличе у вас тривогу (у хорошому сенсі), а нарощування партитури б’є в саме серце та ідеально формує напругу”, — кінокритик Андре Сент-Альбен.
Інші визначають стрічку, масштабнішою за “Дюну” і кращою, з того, що коли-небудь робив Нолан.
“Він більший за масштабом, ніж “Дюна”. Це щось неймовірне. Можливо, найбільший фільм усіх часів. Не думаю, що колись ще створять щось з такими масштабами”, — пише журналіст Брендон Норвуд.
Цікаво, що навіть ті, хто подивився неякісну бутлег-версію, теж висловлюють захоплення.
“Можу сказати, що ще ніколи не був так захоплений переглядом злитого в інтернет низькоякісного матеріалу. Найкраще, що я можу описати, це поєднання сирості “Дюнкерка” з постійно наростаючою напругою навколо “Тенета” та “Оппенгеймера”, — пише один з глядачів в соцмережах.
Нагадаємо, що головну роль взяв на себе Метт Деймон, його сина Телемаха зіграв Том Голланд, а дружину Пенелопу — Енн Геттевей. Серед решти акторського складу з’являються Шарліз Терон, Лупіта Ніонго, Роберт Паттінсон, Зендея, Джон Бернтал, Бенні Сафді, Елліот Пейдж, Джон Легуізамо та ін.
“Перші шість хвилин фільму демонструють неймовірну операторську роботу та феноменальну здатність Нолана передавати відчуття масштабу. Кілька сцен просто захоплюють дух; момент, коли коня затягують всередину міських стін, справді вражає, коли так багато статистів намагаються тягнути його по землі. Тим часом увага також зосереджена на переживаннях Одіссея та його людей, коли вони хитаються та намагаються втримати рівновагу в рухомому коні. Все це абсолютно приголомшливо і доводить, що “Одіссея” стане одним із найгарніших фільмів 2026 року”, — підсумовує Том Бекон з Comicbook.
Прем’єра “Одіссеї” запланована на 17 липня 2026 року.
Ledger Nano X — це другий апаратний гаманець, випущений компанією Ledger. У цьому матеріалі я поділюся власним досвідом використання пристрою та своїми думками про те, чи справді він є найкращим гаманцем на ринку.
Зміст
Короткий підсумок огляду Ledger Nano X
Ledger Nano X уже давно вважається одним із найпопулярніших апаратних гаманців серед криптоінвесторів — і у 2025 році він усе ще актуальний. Цей пристрій створений для тих, хто хоче отримати високий рівень безпеки, не жертвуючи зручністю. Гаманець підключається як через Bluetooth, так і через USB-C, що дозволяє безпечно керувати криптоактивами як з комп’ютера, так і з мобільного пристрою.
Ви можете встановити до 100 застосунків одночасно, а це означає, що можна зберігати, надсилати та отримувати понад 15 000 монет і токенів безпосередньо через нещодавно перейменований застосунок Ledger Wallet (раніше відомий як Ledger Live). Усі активи — від Bitcoin та Ethereum до популярних ERC-20 токенів і стейблкоїнів — керуються з одного зручного дашборда.
Ledger Nano X на крок попереду більшості апаратних гаманців, представлених сьогодні на ринку. Збільшена місткість для монет у поєднанні з підтримкою Bluetooth робить його потужним інструментом для управління криптоактивами. Водночас користувацький досвід усе ще потребує доопрацювання. Якщо коротко — це і є Ledger Nano X. Якщо ж вас цікавить детальний огляд мого досвіду використання Nano X, читайте далі.
Апаратний гаманець — це невеликий пристрій, який зберігає приватний ключ до вашої криптовалюти. Його головна особливість у тому, що приватний ключ ніколи не покидає межі пристрою, тобто завжди залишається офлайн (це також називають холодним зберіганням). Навіть коли ви надсилаєте кошти, підпис транзакції відбувається безпосередньо на самому пристрої, а не на комп’ютері, до якого він підключений.
Саме тому апаратний гаманець можна під’єднувати навіть до комп’ютера з вірусами або шкідливими програмами без ризику витоку приватного ключа. Це робить апаратні гаманці надзвичайно популярним варіантом для зберігання криптовалют, особливо у порівнянні з програмними гаманцями, які постійно підключені до інтернету (так звані гарячі гаманці).
Ledger і Nano X
Джерело: 99bitcoins.com
Ledger — одна з двох найбільших компаній на ринку апаратних гаманців на сьогодні (друга — SatoshiLabs, яка стоїть за гаманцями TREZOR). Компанію було засновано у 2014 році, і вона є лідером у сфері безпеки та інфраструктурних рішень для криптовалют і блокчейн-застосунків. У команді Ledger працює понад 700 спеціалістів.
Компанія спеціалізується на розробці продуктів і сервісів для захисту криптоактивів, зокрема таких моделей, як Nano S Plus, Ledger Nano X та найновіший Ledger Stax.
Головна відмінність Nano X від попередніх моделей — це підтримка Bluetooth, яка дозволяє керувати пристроєм через смартфон, а не лише з настільного комп’ютера.
Що в коробці?
Nano X постачається у стильній упаковці. Усередині ви знайдете сам пристрій, кабель USB-C, інструкції, картки для запису recovery seed, брелок та фірмові наліпки Ledger. Грубі кнопки, які раніше розташовувалися зверху пристрою, тепер акуратно інтегровані в корпус і майже непомітні. Загалом дизайн виглядає дуже естетично.
Джерело: 99bitcoins.com
Налаштування Nano X
Процес налаштування Nano X складається з кількох етапів.
Крок 1: Встановлення PIN-коду
Після першого увімкнення пристрій запропонує вам вибрати PIN-код довжиною від 4 до 8 цифр. Перемикання між цифрами відбувається за допомогою кнопок, а підтвердження («enter») — натисканням обох кнопок одночасно.
Крок 2: Запис seed-фрази
Seed-фраза — це фактично пароль до вашого гаманця. Вона повинна зберігатися в безпечному та прихованому місці. Під час ініціалізації пристрою ви отримаєте 24 слова, які потрібно записати на папір і зберегти. У разі втрати, поломки або крадіжки пристрою ви зможете відновити доступ до коштів за допомогою цієї seed-фрази на новому пристрої.
Джерело: 99bitcoins.com
Оскільки seed-фраза є надзвичайно важливою, після запису вас попросять повністю підтвердити її. На відміну від процесу налаштування TREZOR, у гаманцях Ledger цей крок неможливо пропустити. Я розумію, чому Ledger наполягає на цьому, але особисто для мене це дещо незручно — я б хотів мати можливість пропустити цей етап і повернутися до нього пізніше.
Крок 3: Підключення Nano X до мобільного пристрою
Тепер починається найцікавіше — підключення Nano X до смартфона. Раніше гаманцями Ledger можна було керувати лише через настільне програмне забезпечення Ledger Live. Nano X також підтримує керування через мобільний застосунок Ledger Live.
На перший погляд процес підключення має бути простим, але, на жаль, у моєму випадку це було не так. Процес виявився дещо «глючним», і мені знадобилося дві спроби, щоб усе запрацювало. Коли ви починаєте керувати пристроєм через застосунок, усе стає ще складніше. Майже кожна дія в застосунку потребує очікування Bluetooth-з’єднання та підтвердження на самому пристрої. Досить часто опція «approve» не з’являється одразу, і доводиться чекати кілька секунд, поки дія підтвердиться автоматично.
Крок 4: Встановлення застосунків
Після успішного підключення ви можете встановлювати різні застосунки залежно від тих монет, які плануєте використовувати.
Джерело: 99bitcoins.com
Крок 5: Додавання акаунтів
Цей етап виявився для мене найбільш заплутаним. Після встановлення застосунку Bitcoin я був упевнений, що вже готовий до роботи. Виявилося, що потрібно додатково створити Bitcoin-акаунт на пристрої, але інтерфейс ніяк не підказує цього. Звісно, на сайті Ledger є детальний гайд, але як досвідчений біткоїнер я очікував більш інтуїтивного процесу. Після приблизно п’яти хвилин пошуків я нарешті знайшов цей пропущений крок, і далі керування пристроєм стало значно зрозумілішим.
Після налаштування та певного часу використання Nano X я можу сказати, що маю змішані почуття. З одного боку, це безумовно крок уперед порівняно з попередніми моделями та іншими апаратними гаманцями. З іншого — інтерфейс не такий інтуїтивний, як хотілося б, а Bluetooth-підключення часто ускладнює виконання дій.
Можливо, це пов’язано з технічними обмеженнями, про які я не знаю. Але якщо продукт орієнтований на масового користувача, йому явно не завадило б ще трохи «відшліфувати» користувацький досвід.
Підтримувані монети Ledger Nano X
Ledger Nano X підтримує понад 5 500 монет і токенів. Основні криптовалюти можна надсилати та отримувати безпосередньо через інтерфейс Ledger Live. Ось перелік найпопулярніших підтримуваних монет:
Bitcoin (BTC)
Ethereum (ETH)
USD Tether (ERC20) (USDT)
Chainlink (LINK)
Polkadot (DOT)
Solana (SOL)
Polygon (MATIC)
Ripple (XRP)
Litecoin (LTC)
Dogecoin (DOGE)
Для взаємодії з NFT на базі Ethereum та Polygon вам потрібно завантажити та встановити програмне забезпечення Ledger Live на комп’ютер або мобільний пристрій. Перед купівлею конкретного гаманця обов’язково переконайтеся, що потрібні вам монети підтримуються цим пристроєм. Актуальний список підтримуваних монет завжди доступний на офіційному сайті Ledger.
Скільки коштує Nano X?
Ціна Ledger Nano X становить приблизно 6300 грн, що майже вдвічі дорожче за Nano S Plus (3999 грн). Фактично ви доплачуєте за підтримку Bluetooth. Хоча різниця в ціні суттєва, додаткова функціональність того варта. Можливість керувати апаратним гаманцем безпосередньо зі смартфона — це великий плюс.
Порівнюючи Nano X з конкурентами, я вважаю, що цей криптогаманець Ledger має перевагу. Він підтримує Bluetooth і доступний для використання на мобільних пристроях як з iOS, так і з Android, чого бракує Nano S Plus.
Гаманці TREZOR також можна використовувати зі смартфонами, але лише на Android, оскільки для iOS досі немає застосунку Trezor Suite. У порівнянні з Trezor Model T (5999 грн), Nano X поступається лише відсутністю сенсорного екрана, що, по суті, не є критичною перевагою. Новітній гаманець TREZOR — Trezor Safe 3 (4999 грн) — є справді якісним продуктом і також має Secure Element-чип, як у Ledger, але не підтримує Bluetooth.
Що нового в Ledger Nano X
Останнім часом Ledger внесла низку важливих змін до Nano X та всієї екосистеми. Від повного ребрендингу застосунку до нових функцій безпеки та оновлень прошивки — додано чимало нововведень, спрямованих на підвищення безпеки, прозорості та зручності використання. Якщо ви читали старі огляди або користувалися Nano X раніше, ось що змінилося з того часу.
Зміна назви застосунку
Основний застосунок Ledger було перейменовано з Ledger Live на Ledger Wallet. Ця зміна підкреслює його розширену роль як повноцінної платформи для управління криптоактивами. У застосунку, як і раніше, можна купувати, продавати, обмінювати та стейкати криптовалюту, але інтерфейс став оновленим і більш зручним. Для мобільних користувачів керування апаратним гаманцем через Bluetooth стало швидшим і стабільнішим порівняно з 2024 роком.
Оновлення безпеки та нові функції
Останнім часом Ledger додала кілька важливих оновлень безпеки, серед яких:
Clear Signing: ця функція відображає всі деталі транзакції простою мовою безпосередньо на екрані пристрою перед підтвердженням. Ви бачите актив, суму, адресу призначення та dApp, з яким взаємодієте. Це усуває здогадки під час роботи зі смартконтрактами.
Transaction Check: новіший інструмент, який симулює транзакцію перед її виконанням і попереджає про потенційні ризики, зокрема заміну контрактів або підозрілі адреси. Наразі працює для Ethereum та інших EVM-сумісних активів і з часом буде розширений на інші мережі.
Обидві функції є частиною курсу Ledger на відкриті стандарти та безпечніше використання смартконтрактів. Вони не замінюють підтвердження дій на самому пристрої — кожну операцію все одно потрібно підтвердити фізичними кнопками, — але значно спрощують розуміння того, що саме ви підтверджуєте.
Тепер Ledger називає свої апаратні пристрої «signers». Nano X вважається класичним Bluetooth-signer’ом і займає середню позицію між базовим Nano S Plus і преміальними моделями на кшталт Nano Gen5, Ledger Stax та Ledger Flex.
Nano Gen5, представлений у жовтні 2025 року, отримав автентифікацію з використанням ШІ та сучасний сенсорний екран. Водночас Nano X залишається надійним варіантом середнього рівня, який простіший у використанні та доступніший за ціною.
Мобільна прошивка та оновлення
Починаючи з версії прошивки 2.4.1, власники Nano X можуть оновлювати пристрій бездротово через Bluetooth за допомогою мобільного застосунку Ledger Wallet. Це значно спрощує обслуговування для користувачів, які не хочуть підключати гаманець до комп’ютера.
Шукаєте безкоштовну програмну альтернативу?
Ledger Nano X — це преміальний апаратний гаманець, відомий своїм холодним зберіганням, підтримкою Bluetooth і сумісністю з понад 5 500 монетами. Він чудово підходить для офлайн-безпеки та добре інтегрується з застосунком Ledger Live на комп’ютері й мобільних пристроях. Проте ціна і дещо складний процес налаштування можуть підійти не всім. Тому пропонуємо нашу добірку найкращого програмного гаманця.
Джерело: 99bitcoins.com
Best Wallet
Best Wallet — це безкоштовний некостодіальний програмний гаманець, створений для зручності та гнучкості. Він підтримує понад 60 блокчейнів, має вбудований DEX для торгівлі, фіатні on/off-ramps та можливість стейкінгу, що робить його багатофункціональним рішенням для управління криптовалютою на ходу.
На відміну від Nano X, Best Wallet не потребує фізичного пристрою чи додаткового налаштування, тому ідеально підходить для щоденної торгівлі та DeFi-взаємодії. Ось його ключові можливості:
Non-custodial з повним контролем над приватними ключами.
Додайте кошти: поповніть гаманець криптовалютою або скористайтеся фіатними on-ramp сервісами.
Висновок — чи вартий Ledger Nano X своїх грошей?
Без сумніву, Ledger доклала чимало зусиль, щоб вивести свою другу модель апаратного гаманця на новий рівень. Поєднання стильного пристрою з функціональним програмним забезпеченням Ledger Live створює потужний інструмент для управління криптоактивами. Водночас Nano X не позбавлений недоліків. Користувацький досвід під час налаштування потребує кращого продумування, а робота з Bluetooth далека від ідеалу.
Попри це, я б однозначно користувався цим пристроєм, навіть з урахуванням його мінусів. Він не ідеальний, але все ж перемагає більшість конкурентів. Водночас Best Wallet пропонує неперевершену зручність і широкий функціонал для активних трейдерів і учасників DeFi — і все це без необхідності мати фізичний пристрій.
Сервіс Waymo продовжує фіксувати серію нестандартних ситуацій у своїх автономних таксі. Після нещодавнього випадку в Сан-Франциско, коли вагітна жінка народила просто в роботаксі дорогою до лікарні, та блокування руху кортежу Камали Гарріс, тепер компанія отримала нову хвилю уваги — значно менш приємну.
У Лос-Анджелесі жінка викликала роботаксі Waymo для своєї доньки, але, відкривши багажник, застала там незнайомого чоловіка. У відео, яке миттєво стало вірусним у TikTok, вона кричить:
“Якого біса ти у багажнику?!”.
Чоловік відповів:
“Це лайно мене не випускає!”, — при цьому бив кулаками по спинці сидіння.
У наступному відео жінка спілкується з представником Waymo вже після того, як двоє поліцейських вивели чоловіка з машини та затримали на тротуарі.
Багатьох шокувало, як таке взагалі можливо в роботаксі — ситуація, яка навряд чи сталася б з водієм-людиною, адже стороннього в багажнику помітили б одразу. У Waymo інцидент не заперечили:
“Ми прагнемо забезпечити безпеку пасажирів і завоювати довіру спільнот, у яких працюємо. Цей досвід є неприпустимим, і ми вже впроваджуємо зміни, щоб усунути причини”, — заявив речник компанії в коментарі New York Post.
Спільнота Waymo на Reddit теж була вражена. Дехто спершу вважав відео фейком, але після підтвердження компанії, не приховував сорому. Інші обурювалися поведінкою чоловіка.
Користувачі активно обговорювали, як чоловік потрапив у багажник модифікованого під роботаксі Jaguar I-Pace. Очевидно, він проліз туди з салону, адже при підході ззовні це було б легко видно на камерах. Деякі зазначили, що вибратися можна просто натиснувши велику кнопку складання сидіння — тож “неможливість вийти” звучить дивно. Інші ж припускали, що мотив був “якимось дивним фетишем”.
Спільнота закликає Waymo додати датчики в багажнику або додаткові механізми безпеки, адже компанія вже стикалася з критикою через інші інциденти. Нещодавно роботаксі прорвалося просто через поліцейську операцію в центрі Лос-Анджелеса.
Сервіс працює в Лос-Анджелесі, Сан-Франциско, Фініксі, Атланті та Остіні, а Waymo продовжує готуватися до розширення в інші міста, тож і випадків, очевидно, буде більше.
Що ж до матері, яка зняла вірусне відео — компанія компенсувала їй поїздку кредитом на майбутній виклик.
HBO представив тизер серіальних прем’єр 2026 року: він включає як нові назви, так і продовження відомих шоу, таких як “Дім дракона” чи “Ейфорія”.
“Ти маєш вирішити, чого хочеш”, — каже персонаж Корліс Веларіон (Стів Туссен) з “Дому дракона” у тизері. Далі нам показують Алісенту Гайтауер (Олівія Кук), яка попереджає, що Рейніра (Емма Д’арсі) зробить щось жахливе.
На кадрах з третього сезону “Ейфорії” Ру Беннет (Зендея) танцює з іншими жінками на вечірці, в якийсь момент лишається на самоті у церкві, а згодом біжить вулицею, озираючись назад. Далі нам демонструють кілька кадрів з іншими персонажами: Лексі (Мод Апатоу) посміхається за столом з чоловіками, Медді (Алекса Демі) поправляє макіяж, Нейт (Джейкоб Елорді) танцює перед телевізором у розстебнутій сорочці, Кессі (Сідні Свіні) посміхається в костюмі кролика, а Джулс (Хантер Шафер) відкидає голову на сидіння.
І нарешті “Ліхтарі” з персонажами DC: до цього ми бачили лише одне офіційне зображення майбутнього шоу, тоді як тизер дарує трохи кадрів в русі.
“Я все життя для цього тренувався”, — каже Гел Джордан (Кайл Чандлер) за кермом авто, лишає кільце Зеленого ліхтаря і за кілька секунд вистрибує з водійського сидіння. Машина в цей час з’їжджає з обриву, а Джон Стюарт (Аарон П’єр) все ще перебуває всередині.
Серед іншого тизер пропонує новий погляд на третій сезон серіалу Лізи Кудроу “Повернення”, “Напівлюдину” Річарда Ґадда, другий сезон “Дюни: Пророцтва”, “Індустрії”, “Пітта”, спінофу “Теорії великого вибуху” та “Лицаря сімох королівств”. Відео супроводжуються підписом “вийде у 2026-му”, тож наступний рік принесе багатенько прем’єр — питання лишається в тому, чи дивитимемося ми все це на HBO.
Xiaomi Auto вирішила не чекати “правильного моменту” й запустила одразу три великі автомобільні проєкти. Компанія формує повноцінну лінійку електромобілів, яка закриває ключові сегменти ринку: сімейний повнорозмірний кросовер, високопродуктивну модель для поціновувачів швидкості та преміальний седан для вимогливих власників.
Першим у тріо йде гігантський електрокросовер Xiaomi YU9 — майбутній флагман Xiaomi для родин. Довжина понад 5,2 м робить його навіть більшим за Mercedes EQS SUV. Всередині можна розмістити шість або сім пасажирів, тому модель розрахована на великі сім’ї й тривалі поїздки. Щоб зняти питання із запасом ходу, Xiaomi встановлює просунутий силовий модуль розширеного радіусу дії. Він дає можливість їздити на чистій електротязі в місті й без хвилювання долати далекі дистанції. YU9 напряму націлюється на Li Auto L9 та Aito M9, а серйозність підготовки підтверджує участь Лея Цзюня в суворих зимових і висотних тестах на плато Памір у Сіньцзяні — отже, SUV уже близький до масового запуску.
Другий проєкт — високошвидкісний електромобіль Xiaomi YU7 GT, створений на базі поточного YU7, але з чітким фокусом на динаміку. Команда інженерів ретельно налаштовує шасі, працює з підвіскою й кермуванням, щоб зробити реакції максимально точними. Паралельно оптимізують електричну силову установку та тепловий менеджмент, щоб двигуни витримували інтенсивні навантаження. Xiaomi YU7 GT неодноразово тестували на легендарній трасі Нюрбургринг у Німеччині. Саме ця модель має стати “прохідним квитком” Xiaomi до Європи та конкурувати з Tesla Model Y Performance у сегменті швидкісних електрокросоверів.
Замикає преміальну трійку Xiaomi SU7 L — подовжена, дорожча й комфортніша версія вже знайомого седана SU7. Шпигунські фото показують значне збільшення задньої частини кузова за B-стійкою, щоб дати пасажирам другого ряду більше простору. Загальна довжина має перевищити 5,2 м, а колісна база — понад 3,1 м. За габаритами й призначенням SU7 L наближається до Porsche Panamera, причому розташовується між стандартною та подовженою Executive-версіями.
Одночасна підготовка трьох великих моделей — YU9, YU7 GT та SU7 L — показує, що Xiaomi не просто нарощує присутність на ринку, а планує швидко закріпитися в різних цінових і функціональних нішах. Компанія прагне, щоб майже кожен потенційний покупець електромобіля отримав релевантний варіант із логотипом Xiaomi.
Apple почала підбивати підсумки й опублікувала список найпопулярніших застосунків та ігор 2025 року в App Store. Рейтинги складені окремо для iPhone та iPad, у безплатних і платних категоріях. Це щорічний зріз того, що встановлювали користувачі, і водночас непоганий індикатор того, як змінювалися цифрові звички протягом року.
У категорії безплатних застосунків для iPhone перше місце посів ChatGPT. За ним — Threads, Google, TikTok і WhatsApp. Єдиним іншим чатботом у топі став Google Gemini, який замкнув список на десятому рядку. Серед платних застосунків користувачі найчастіше купували HotSchedules, Shadowrocket і Procreate Pocket.
У розділі безплатних ігор для iPhone лідерами стали Block Blast, Fortnite та Roblox. А серед платних — Minecraft, карткова стратегія Balatro і популярна вечіркова гра Heads Up.
На iPad картина трохи інша. Найбільше завантажень серед безплатних застосунків набрав YouTube, далі — ChatGPT, Netflix, Disney+ та Amazon Prime Video. У платному сегменті перші позиції традиційно зайняли творчі інструменти: Procreate, Procreate Dreams, forScore, ToonSquid і Nomad Sculpt.
У топі безплатних iPad-ігор опинилися Roblox, Block Blast і Fortnite. А серед платних знову лідирував Minecraft, за ним — Geometry Dash і Stardew Valley.
Окремо Apple назвала найпопулярніші ігри сервісу Apple Arcade у 2025 році. Серед лідерів — NFL Retro Bowl ’26, NBA 2K25 Arcade Edition і Balatro+.
Статистика 2025 року показує, що попит на ШІ-застосунки стабільно зростає, а кросплатформові ігри й надалі тримають верхівку рейтингів. Отже користувачі все частіше шукають універсальні інструменти та розваги, які працюють однаково добре і на смартфоні, і на планшеті.
В Україні стартували офіційні продажі бренду Zewood, що виробляє дерев’яний домашній декор для фанатів фентезі, кіно, коміксів та ігор. Компанія працює з натуральною деревиною та поєднує лазерне гравіювання, 3D-моделювання й ручне оздоблення, завдяки чому декор виглядає деталізовано та атмосферно. Zewood має офіційні ліцензії Harry Potter, The Lord of the Rings, DC та Game of Thrones, тож українські покупці тепер можуть отримати легальний преміальний мерч із популярних франшиз — у форматі настінних годинників, дерев’яних постерів, карт чи (це нам сподобалося найбільше) ключниць з магнітними брелоками.
Настінні дерев’яні годинники — від магічних мотивів до епічних сюжетів
Декоративні карти та панно — з деталізованим лазерним гравіюванням і багатошаровими елементами
Дерев’яні постери — художні композиції у преміальному виконанні
Ключниці та настінні аксесуари — практичні речі з улюбленими сюжетами та дизайнами.
Для охочих зробити подарунок персональним Zewood пропонує кастомізацію: гравіювання імені, дати чи символу.
Хто стоїть за брендом
Засновники бренду — Анна та Андрій Панько. Ілюстрація: Zewood
Бренд Zewood створили українські підприємці та митці Анна й Андрій Панько, які поєднали багаторічний досвід у дизайні, виробництві та любов до фентезі-світів. Андрій — серійний підприємець із родинними традиціями столярства та прихильністю до Lord of the Rings, а Анна — дизайнерка та фотограф, яка навчалася у Австрії та формує творчу естетику бренду. Засновники особисто залучені в усі етапи виробництва, працюють разом із командою ремісників і дизайнерів, створюючи унікальні дерев’яні вироби на сертифікованих виробничих потужностях у ЄС.
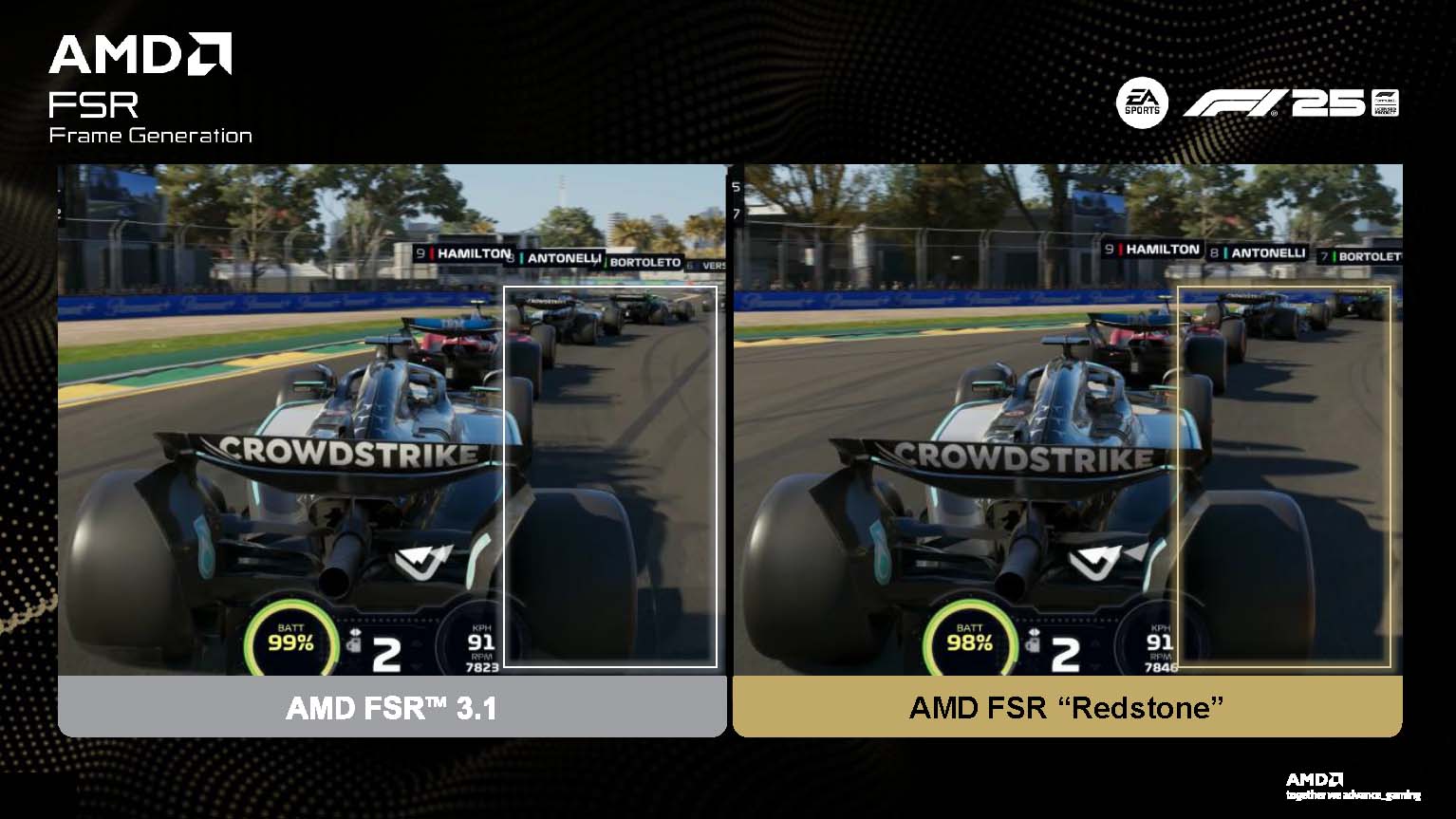
Сьогодні AMD офіційно запустила пакет FSR Redstone, призначений лише для відеокарт RDNA4. Раніше Radeon RX 9000 вже отримали першу з чотирьох технологій, ML Ray Regeneration, з Call of Duty: Black Ops 7.
Попри очікування, AMD не запускає всі чотири основні компоненти Redstone навіть зараз, оскільки принаймні один буде доступний лише у 2026 році. А одна з функції, та сама регенерація променів, поки буде обмежена однією COD. AMD офіційно змінює назву стека на просто FSR, котра відтепер не обмежується лише масштабуванням та генерацією кадрів. Компанія стверджує, що Redstone забезпечить в середньому до 3,3 раза кращу продуктивність порівняно з іграми в “рідній” роздільній здатності 4K.
AMD копіює підхід NVIDIA до DLSS, додаючи більше технологій під абревіатуру FSR. Фактично, масштабування FSR не оновлюється, на слайді чітко зазначено “раніше FSR 4”. Компанія повторює, що ця технологія доступна лише на відеокартах серії Radeon RX 9000 і лише з іграми, які вже підтримують FSR 3.1. Ось що конкретно доступно після сьогоднішнього релізу:
FSR Upscaling — 200+ ігор до кінця цього року
FSR Frame Generation — 30+ ігор до кінця року
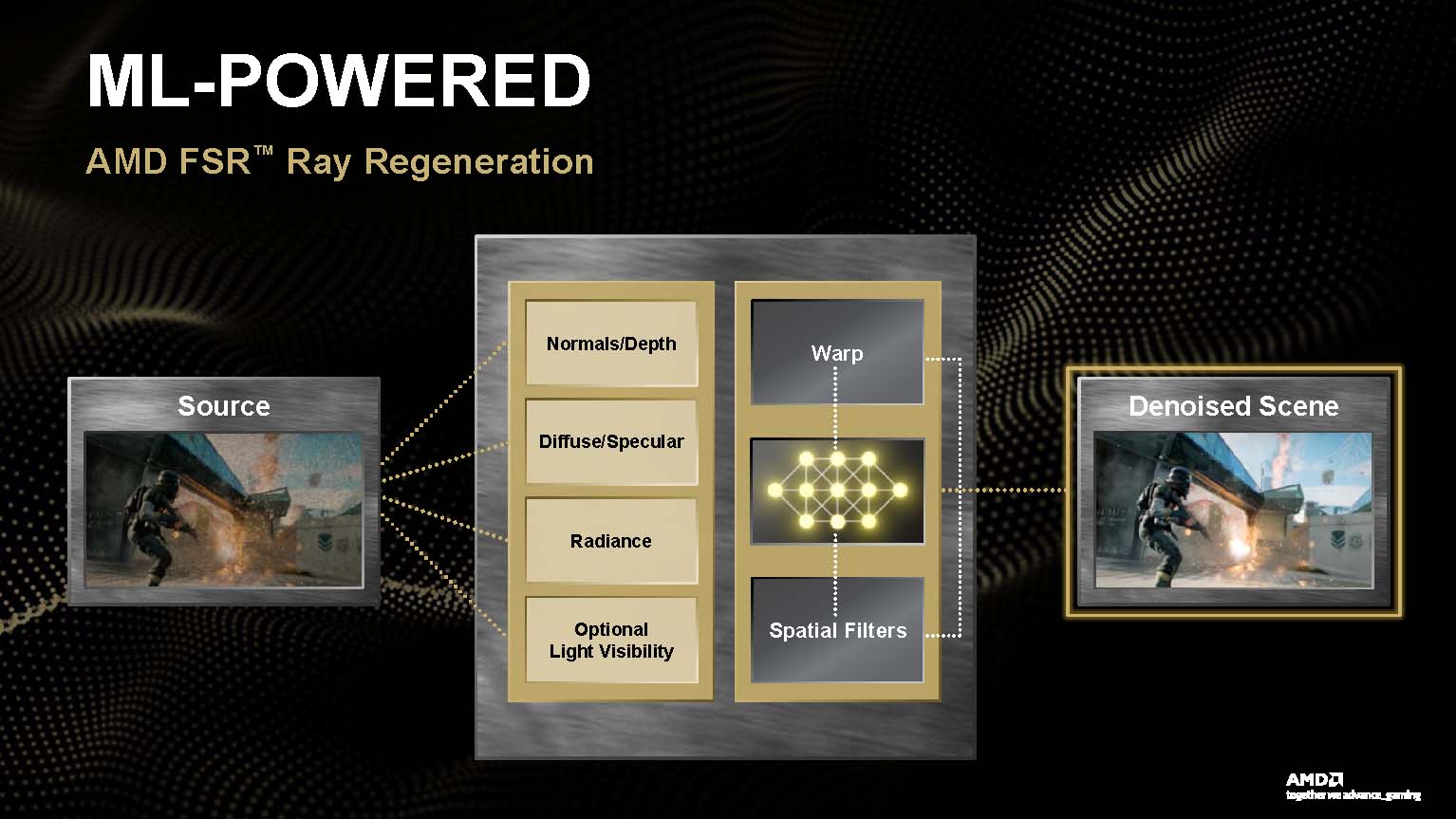
FSR Ray Regeneration — тільки Black Ops 7, більше колись пізніше
FSR Radiance Caching — запуск у 2026 році
Генерація кадрів FSR, яку раніше рекламували як ML Frame Generation (деякі користувачі помилково називали її багатокадровою генерацією), також є частиною Redstone. AMD стверджує, що вона розроблена для забезпечення “плавної та високої частоти кадрів” і що вона використовує нейронну мережу, навчену на вимогливих сценаріях. Вона акцентує на обмеженні артефактів та виправленні тіней.
FSR Radiance Caching прискорює трасування променів та зменшує витрати на кешування сяйва. Це метод глобального освітлення, коли графічний процесор обчислює “важке” непряме освітлення в обмеженому наборі точок сцени, зберігає ці результати, а потім використовує в інтерполяції для сусідніх пікселів. Це зменшує кількість променів та відбитків, які потрібно трасувати, тому непряме світло, розтікання кольорів та м’яке відбиття можна виводити швидше, якщо освітлення не змінюється надто різко між кешованими точками.
FSR Ray Regeneration з’явиться в іграх у невизначені терміни, оскільки впровадження технології значною мірою залежить від розробників. Регенерація променів забезпечує реалістичне освітлення та відблиски, подібно до роботи NVIDIA DLSS Ray Reconstruction.
Також сьогодні вийшов FSR Redstone SDK. Він представлений у вигляді простої інтеграції DLL, тому незабаром можна очікувати кращої підтримки ігор. Але навіть попри це, загальний реліз стеку не такий масштабний як очікувалося — щось буде колись пізніше, а щось не змінюється.
Саймон Франґлен був аранжувальником та автором пісень в оригінальному “Аватарі” 2009 року і написав музику до сиквелу 2022 року, однак третій фільм вимагав куди більше зусиль — як технічних, так і тематичних. У підсумку загальний обсяг музики у “Вогні та попелі” ледь не дорівнював тривалості самого фільму.
“З погляду масштабу того, що нам довелось створити, ця музика перевершує все те, що я робив раніше”, — розповідає Франґлен в інтерв’ю IndieWire.
При цьому перша пісня для “Аватар: Вогонь і попіл” була створена ще 7 років тому, тоді як основну частину Франґлен написав протягом 2,5 років — ноти зайняли 1907 сторінок.
“Фільм триває 3 години 15 хвилин і в ньому 3 години 4 хвилини та 16 секунд звучить музика. Тож у мене є близько 10 хвилин відпочинку за гарну поведінку”, — жартує композитор.
Складність роботи Франґлена полягала в тому, що “Вогонь і попіл” досить часто переходить між жанрами й охоплює широкий тональний діапазон: від інтимно романтичного до сумного. До прикладу, сцени із Джейком та Нейтірі вимагали відчуття дистанції та спустошеності втратою, а от з Торговцями вітру можна було погратись темами в стилі голлівудських пригодницьких фільмів 1930-х і 1940-х років. В другому випадку композитору довелось не лише створити музику, а й розробити інструменти, на яких персонажі грають в кадрі.
“Мені довелося розробляти справжні інструменти, а в “Аватарі” ми не можемо нічого вигадувати”, — каже Франґлен, посилаючись на вимогу Джеймса Кемерона щодо реалістичності. “Я бачив їх як фінікійських торговців давнини. Вони набагато витонченіші, ніж інші клани, яких ми зустрічали в минулому. Їм не можна просто так дати звичайні бас-гітару і барабани. Тож я намалював кілька інструментів і вирішив зробити пластик для барабанів з того ж матеріалу, що й вітрила. Плюс, я хотів, щоб струнні інструменти відчувались як такелаж корабля, бо це кочівники. У них повинні бути інструменти, які відображають те, чим вони займаються”.
Розробки Франґлена віддали до художнього відділу для створення рендерів, а потім майстер з реквізиту Бред Елліотт надрукував необхідні елементи на величезному 3D-принтері.
Для іншого нового клану в “Аватар 3”, племені Вогню, композитор теж мав особливий підхід.
“Це агенти хаосу і я хотів, щоб їхня музика мала вісцеральний характер. 10 років тому я був у Внутрішній Монголії, і там був струнний інструмент під назвою морінхур, який може видавати справжню лють. Тому я формував структуру навколо нього”, — каже Франґлен і одразу додає, що використав для різноманітності тритон — музичний інтервал, який прозвали “диявольським” через напружене звучання. “Він ніколи не буває повністю чітким. Ви чуєте його, коли плем’я вперше атакує, а пізніше це стає їхнім мотивом”.
Майже вся музика до “Аватар 3” була записана в Лос-Анджелесі на майданчику Fox за участі 215 музикантів: включно з оркестром зі 100 музикантів, хорами, солістами та ін.
“Я хотів створити органічне відчуття, що за допомогою музики розповідається історія”, — каже композитор. “Створити емоційний зв’язок”.
“Аватар: Вогонь і попіл” продовжує події фільму “Шлях води” 2022 року, який завершився смертю Нетеяма, сина Джейка та Нейтірі. Сум родини порушує нова загроза у вигляді племені Вогню, ворожої групи мешканців На’ві на чолі з мстивою Варанг Уни Чаплін. Свої ролі у стрічці повторюють Сем Вортінгтон, Зої Салдана, Сігурні Вівер, Стівен Ленг та Кейт Вінслет. В українських кінотеатрах “Аватар 3” транслюватиметься з 18 грудня.